PhD Thesis
Over the last decade, new applications such as data intensive workflows have hit an inflection point in wide spread use and influenced the compute paradigm of most scientific and industrial endeavours. Data intensive workflows are highly dynamic and adaptable to resource changes, system faults, and also allow approximate solutions to their models. On the one hand, these dynamic characteristics require processing power and capabilities originated in cloud computing environments, and are not well supported by large High Performance Computing (HPC) infrastructures. On the other hand, cloud computing datacenters favor low latency over throughput, deeply contrasting with HPC, which enforces a centralized environment and prioritizes total computation accomplished over-time, ignoring latency entirely. Although data handling needs are predicted to increase by as much as a thousand times over the next decade, future datacenters processing power will not increase as much.
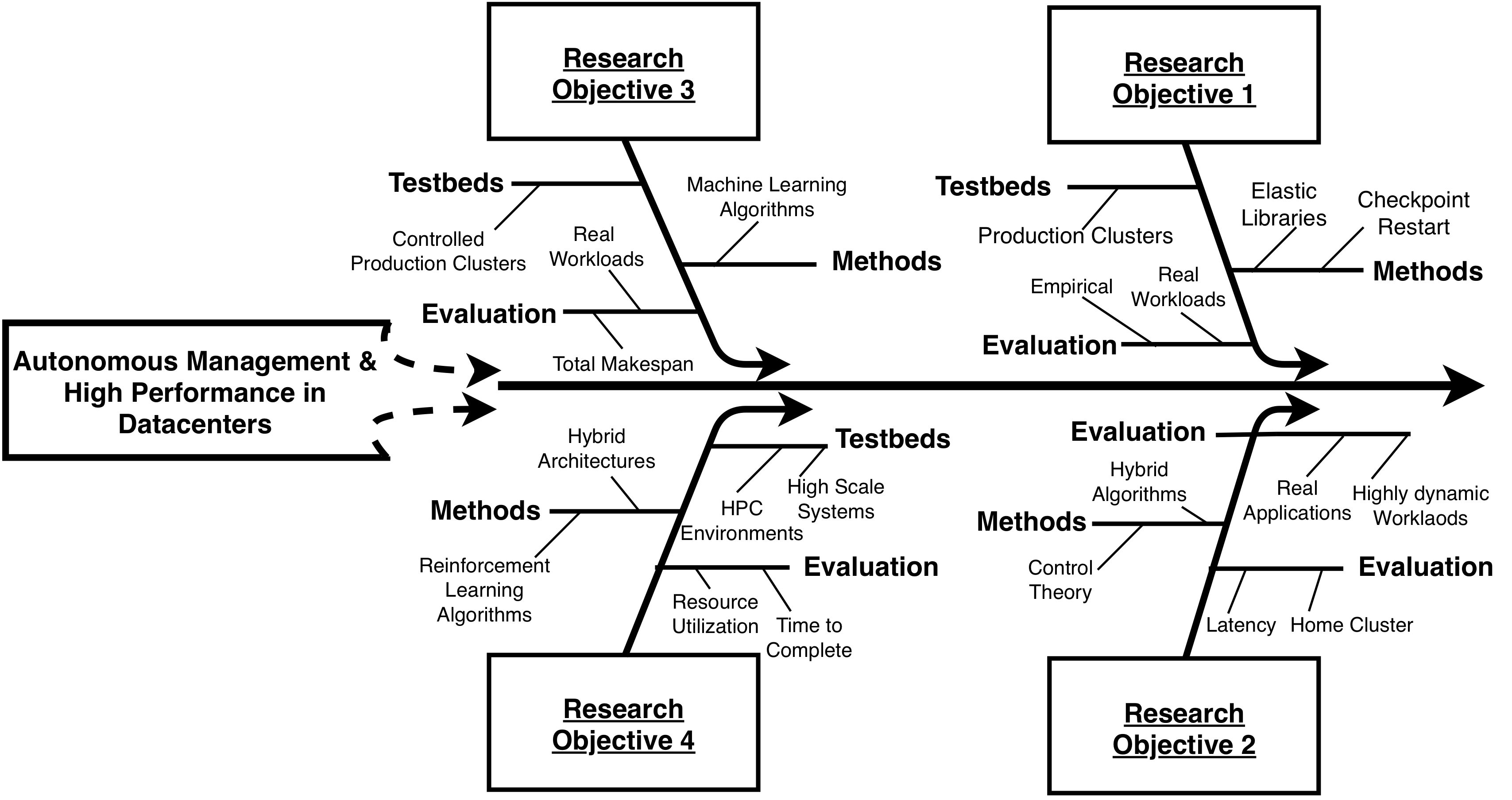
To tackle these long-term developments, this thesis proposes autonomic methods combined with novel scheduling strategies to optimize datacenter utilization while guaranteeing user defined constraints and seamlessly supporting a wide range of applications under various real operational scenarios. Leveraging upon data intensive characteristics, a library is developed to dynamically adjust the amount of resources used throughout the lifespan of a workflow, enabling elasticity for such applications in HPC datacenters. For mission critical environments where services must run even in the event of system failures, we define an adaptive controller to dynamically select the best method to perform runtime state synchronizations. We develop different hybrid extensible architectures and reinforcement learning scheduling algorithms that smoothly enable dynamic applications into HPC environments. An overall theme in this thesis is extensive experimentation in real datacenters environments. Our results show improvements in datacenter utilization and performance, achieving higher overall efficiency. Our methods also simplify operations and allow the onboarding of novel types of applications previously not supported.
i
Results - Papers
The correlation between the different Research Objectives (ROs) of the thesis, with their specific Key Performance Indicators (KPIs) such as CPU, memory, I/O, and network usages to applications' workload helped us design mechanisms to steer web-services and scientific application resource needs in a way where the user performance, application deployment, and overheads were unnoticeable, resulting in improved datacenter utilizaton and improved performance to applications, measured in throughput, resource expenditure, and/or time to complete. This PhD thesis contains a brief description of datacenter infrastructures, related work, challenges regarding datacenter efficiency, a thorough discussion on ways to improve it, and future work. Besides these, we also include the following papers:
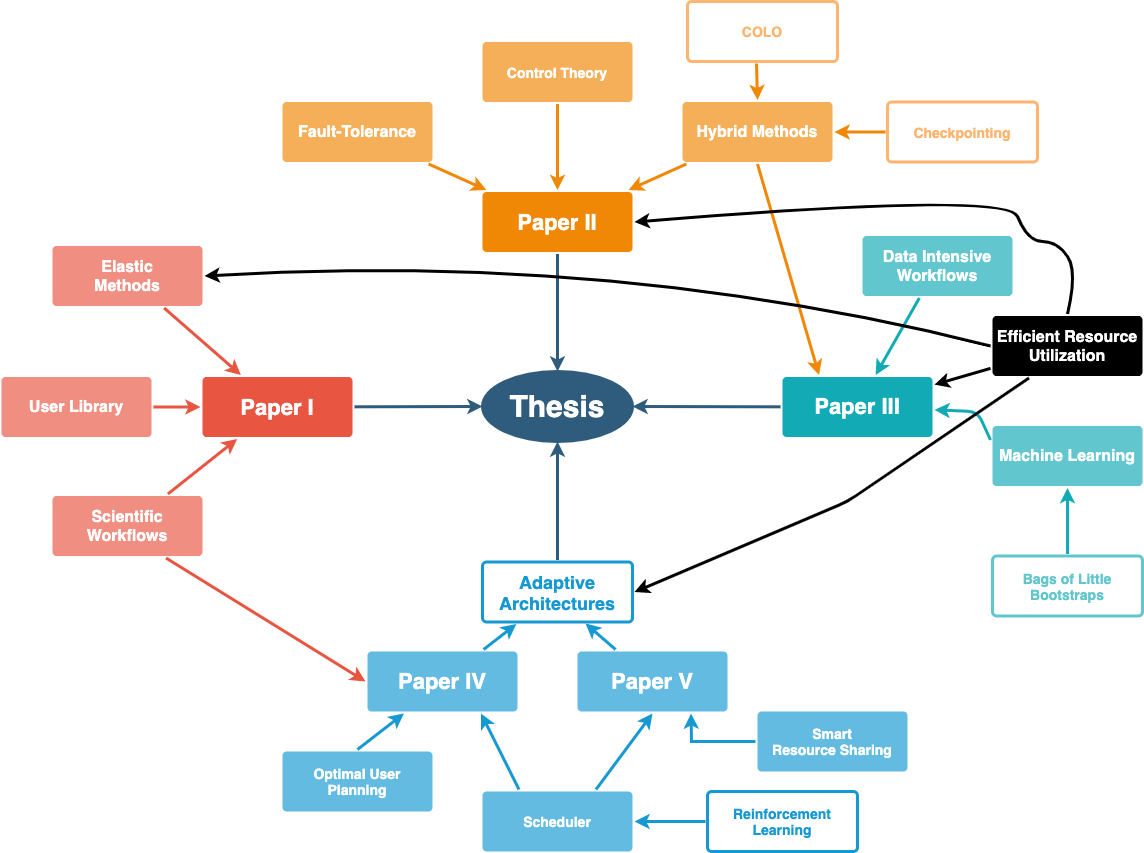
Paper #1 - W. Fox, D. Ghoshal, A. Souza, R. P Gonzalo, and L. Ramakrishnan - E-HPC: a library for elastic resource management in HPC environments (ACM, Proceedings of the 12th Workshop on Workflows in Support of Large-Scale Science (WORKS), 2017) - [PDF]
Paper #2 - A. Souza, A. V. Papadopoulos, L. Tomás, D. Gilbert, and J. Tordsson - Hybrid Adaptive Checkpointing for Virtual Machine Fault Tolerance (IEEE International Conference on Cloud Engineering (IC2E), 2018) - [PDF]
Paper #3 - A. Souza, M. Rezaei, E. Laure, and J. Tordsson - Hybrid Resource Management for HPC and Data Intensive Workloads (19th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (IEEE/ACM CCGrid 2019)) - [PDF]
Paper #4 - A. Souza, K. Pelckmans, D. Goshal, L. Ramakrishnan, and J. Tordsson - ASA - The Adaptive Scheduling Architecture (29th International Symposium on High-Performance Parallel and Distributed Computing (HPDC'2020)) - [PDF]
Paper #5 - A. Souza, K. Pelckmans, and J. Tordsson - A HPC Co-Scheduler with Reinforcement Learning (Submitted) - [PDF]

PhD Kappa - Autonomous Resource Management for High Performance Datacenters (Kappa/Introductory text) - [PDF]
PhD Full Text - [PDF]
PhD Presentation - [PDF]